CAP Theorem for Developers: What It Is and How It Affects Distributed Systems

Introduction to CAP Theorem
Picture yourself as an architect, tasked with designing a sprawling digital metropolis. Your city isn't built from concrete and steel, but from interconnected servers and data centers. As you sketch out your plans, you realize you're facing a fundamental challenge that has puzzled computer scientists for decades: how to create a system that's both rock-solid reliable and lightning-fast responsive, even when parts of it go dark.
This is where the CAP theorem steps onto the stage, like a wise mentor offering guidance in your digital urban planning. Coined by Eric Brewer in 2000, the CAP theorem is a concept that's as central to distributed systems as gravity is to physics. It's a principle that whispers in the ear of every developer working on large-scale applications, reminding them of the inherent trade-offs they'll face.
At its heart, the CAP theorem tells us a bittersweet truth: in a distributed system, you can't have your cake and eat it too. It states that when it comes to Consistency, Availability, and Partition tolerance, you can only choose two out of these three desirable properties at any given time.
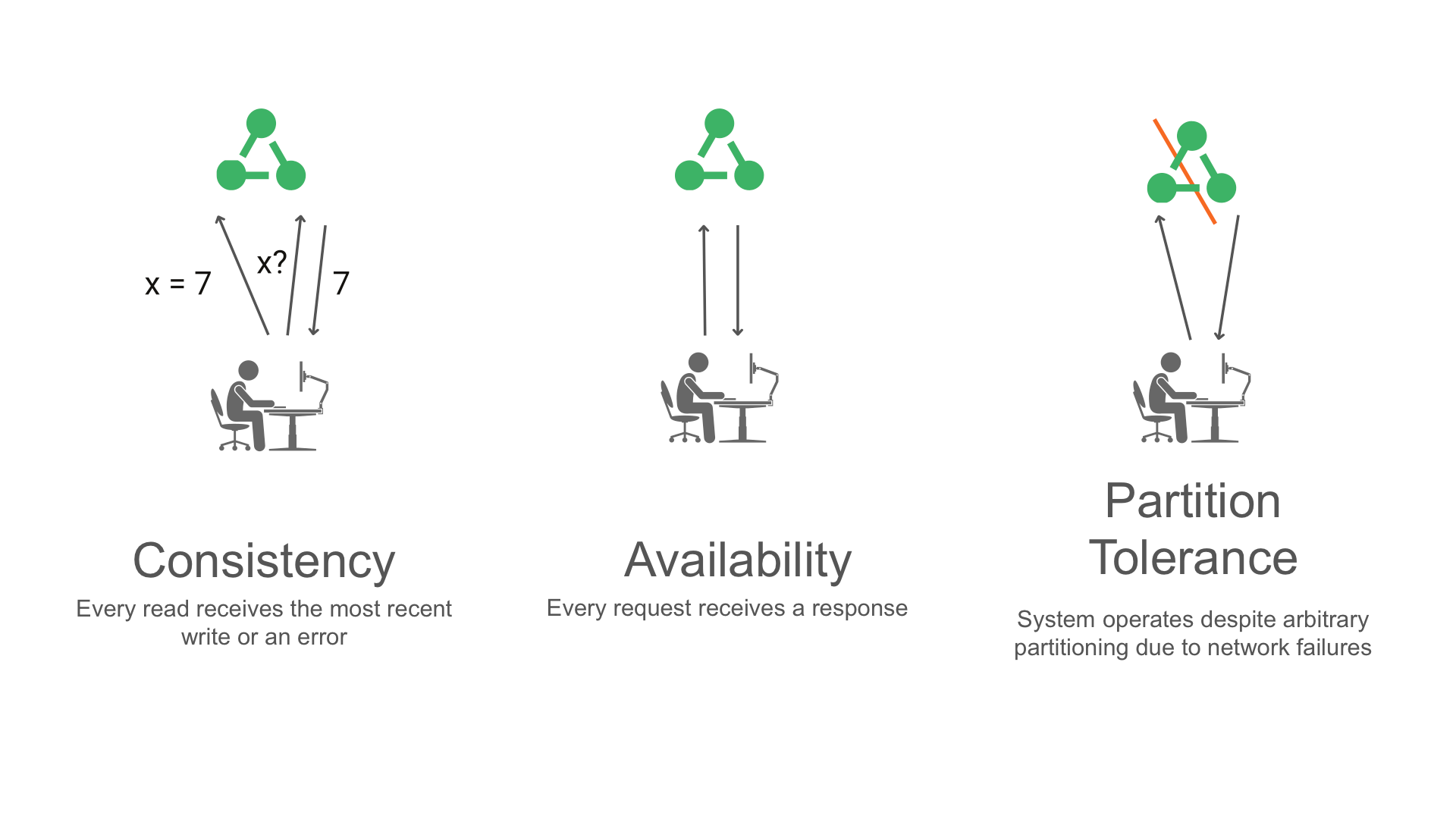
Think of these properties as the three pillars of an ideal distributed system:
- Consistency (C): Every read receives the most recent write or an error
- Availability (A): Every request receives a response, without guarantee that it contains the most recent version of the information
- Partition Tolerance (P): The system continues to operate despite arbitrary partitioning due to network failures.
As we peel back the layers of the CAP theorem, we'll see how these pillars interact, conflict, and compromise. We'll explore why you might choose consistency over availability in some cases, or vice versa. And we'll grapple with the reality that in a world where networks can fail, partition tolerance isn't so much a choice as a necessity.
The CAP theorem isn't just a theoretical concept – it has real-world implications that shape the architecture of systems we interact with daily, from social media platforms to e-commerce giants. As we journey through this article, we'll see how the CAP theorem influences design decisions, affects user experiences, and continues to evolve in the face of new technologies and paradigms.
So, let's discuss all the ideas behind the CAP theorem. It's a journey that will hopefully spark your creativity, give you new knowledge and ultimately make you better architect... and better person. :)
The Three Components: Consistency, Availability, and Partition Tolerance
Let's take a closer look at the three pillars of the CAP theorem, imagining them as the vital organs of our distributed system's body. Each component plays a crucial role, and understanding their nature helps us to see the inherent trade-offs we face with them.

Consistency: The System's Memory
Picture consistency as the system's ability to tell a coherent and truthful story. When we talk about consistency in distributed systems, we're referring to all nodes seeing the same data at the same time. It's like having a group of friends who always have the exact same information, no matter who you ask or when you ask them.
In practice, this means that after an update is made to the system, all subsequent read operations will return that updated value. If you can't guarantee this, you might need to return an error rather than potentially outdated information.
Consider a banking app. When you make a transfer, consistency ensures that your new balance is reflected accurately across all parts of the system. Without it, you might see different balances depending on which server you connect to – a recipe for confusion and potential financial chaos.

Availability: The System's Responsiveness
Availability is like the system's heartbeat – it keeps things alive and responsive. An available system promises to respond to every request, be it a read or a write operation. It doesn't guarantee that the response will contain the most up-to-date information, but it does assure that you'll get a response, not an error.
Imagine a social media platform during a major event. Millions of users are posting updates simultaneously. An available system will ensure that users can continue to post and view content, even if some of the information isn't immediately consistent across the entire network.

Partition Tolerance: The System's Resilience
Partition tolerance is the system's immune system, allowing it to continue functioning even when communication breaks down between its parts. In a distributed system, network failures are not just possible; they're inevitable. Partition tolerance is the ability to handle these failures gracefully.
Think of a global e-commerce platform with data centers across continents. If the transatlantic cable is damaged, partition tolerance ensures that European customers can still shop, even if they can't see real-time updates from American inventory for a while.
The Interplay and Trade-offs
Here's where things get interesting – and challenging. In a perfect world, we'd have all three of these properties working in harmony. But the CAP theorem tells us this isn't possible in a distributed system.

- If we prioritize consistency and availability, we sacrifice partition tolerance. This might work in a small, reliable network, but it's not feasible for most real-world distributed systems.
- If we choose consistency and partition tolerance, we might have to reduce availability. During a network partition, the system might refuse requests to prevent inconsistent data.
- If we opt for availability and partition tolerance, we accept that our data might not always be consistent. This is often the choice for systems that prioritize user experience over absolute data accuracy.
As developers, we're constantly balancing these properties based on our system's needs. A financial system might lean heavily towards consistency, while a content delivery network might prioritize availability.
Understanding these components and their interactions is crucial for designing robust systems, especially distributed systems. It's not about finding a one-size-fits-all solution, but about making informed decisions based on your specific requirements and constraints.
In the next section, we'll explore how these trade-offs play out in real-world scenarios, giving you an understanding of how the CAP theorem shapes the systems we build and use every day.
Understanding Trade-offs in Distributed Systems
Imagine you're a chef in a bustling restaurant kitchen. You've got three prized ingredients - let's call them C, A, and P - but your recipe can only accommodate two of them. This is the essence of the trade-offs we face in distributed systems due to the CAP theorem.
The Balancing Act
In the world of distributed systems, making choices between consistency, availability, and partition tolerance is like walking a tightrope. Each decision tilts the balance, affecting how our system behaves under different conditions.
Imagine a real-time multiplayer game. Players expect immediate feedback (availability) and a fair, synchronized game state (consistency). But what happens when network issues arise (partition)? Do we pause the game to maintain consistency, potentially frustrating players? Or do we allow the game to continue with potential inconsistencies, risking unfair gameplay?
These aren't just theoretical questions - they're the bread and butter of system design decisions that developers grapple with daily.

The CP Approach: When Accuracy is King
Systems that prioritize consistency and partition tolerance (CP) are like precision instruments. They ensure that all nodes have the same data, even if it means some requests might be denied during network partitions.
Database systems often lean towards this approach. For instance, when you're checking your bank balance, you'd rather see an error message than an incorrect amount. In these cases, the system might choose to become temporarily unavailable to avoid serving stale or inconsistent data.
The AP Strategy: Keeping the Show Running
On the other hand, systems that favor availability and partition tolerance (AP) are like the show-must-go-on performers of the tech world. They ensure the system keeps responding, even if the data might not be the latest across all nodes.
Think of a social media feed. If there's a network partition, you might not see the very latest posts from your friends, but the app continues to function, showing you older content rather than an error message.
The CA Compromise: Ideal but Impractical
While it's theoretically possible to have a system that's consistent and available (CA), it comes at the cost of partition tolerance. In the real world of distributed systems, where network failures are a fact of life, this is often an impractical choice.
A small-scale, single-data-center application might achieve CA, but as soon as you scale across multiple data centers or regions, partition tolerance becomes a necessity.
The Art of Choosing
Selecting the right trade-off isn't a one-time decision - it's an ongoing process that evolves with your system's needs and constraints. Here are some factors to consider:
- Data Criticality: How crucial is data accuracy for your application? Financial systems might lean towards CP, while social networks might prefer AP.
- User Experience: Will users tolerate occasional unavailability, or is constant access more important than perfect consistency?
- Scale and Distribution: The more widely distributed your system, the more important partition tolerance becomes.
- Regulatory Requirements: Some industries have strict data consistency requirements that may influence your choices.
- Failure Modes: How does your system behave when things go wrong? Understanding this can help you make more informed trade-offs.
Beyond Binary Choices
It's worth noting that in practice, these trade-offs aren't always binary. Modern distributed systems often employ nuanced strategies that blend aspects of different approaches:
- Eventual Consistency: This model, used by systems like Amazon's Dynamo, accepts temporary inconsistencies but ensures that data will converge to a consistent state over time.
- Tunable Consistency: Some systems allow developers to specify consistency levels for different operations, providing flexibility in how trade-offs are managed.
- Multi-Model Databases: These systems can switch between different consistency models based on the specific needs of different parts of the application.
Understanding these trade-offs is crucial for building resilient, efficient distributed systems. It's not about finding a perfect solution, but about making informed decisions that align with your system's goals and constraints.
CAP Theorem in Practice: Real-world Examples
Theory is good, but without practice it costs nothing. So how about real-world applications? The CAP theorem isn't just an academic concept - it's a guiding principle that shapes the architecture of systems we interact with every day. Here are some examples that bring the CAP theorem to life:

Amazon's Dynamo: Embracing AP for Shopping Carts
Let's take an Amazon during online sale. Millions of shoppers, all clicking 'Add to Cart' simultaneously. Amazon's Dynamo database, which powers their shopping cart system, is a prime example of an AP (Availability and Partition Tolerance) system.
Dynamo prioritizes availability, ensuring that customers can always add items to their carts, even if there's a network partition. It uses eventual consistency, meaning that while your cart might not immediately reflect changes across all nodes, it will eventually catch up.
This approach makes sense for Amazon. A temporarily inconsistent shopping cart is far less problematic than a cart that's unavailable during a busy shopping period. The trade-off? You might occasionally see an item reappear in your cart after removing it, but the system never stops working.

Google's Spanner: Pushing the Boundaries with CP
Now, let's zoom into Google's data centers, where Spanner, their globally distributed database, resides. Spanner is a great case because it aims to provide strong consistency (C) while maintaining partition tolerance (P).
How does it manage this seemingly impossible feat? Through the clever use of atomic clocks and GPS timing, Spanner can synchronize transactions across the globe with remarkable precision. This allows it to maintain consistency even during network partitions.
The trade-off here is potential unavailability during severe network issues. However, for many of Google's services where data accuracy is crucial, this is an acceptable compromise.

Cassandra: Tunable Consistency for Flexibility
Apache Cassandra, used by companies like Netflix and Instagram, offers a more flexible approach. It allows developers to tune consistency levels on a per-operation basis.
Imagine you're building a video streaming service. For user profile updates, you might choose strong consistency to ensure accurate information. But for viewing history, where occasional inconsistency is less critical, you might opt for eventual consistency to improve performance.
This flexibility showcases how modern systems are evolving beyond strict CAP categorizations, allowing developers to make nuanced trade-offs based on specific use cases.

Bitcoin: Eventual Consistency in Decentralized Systems
The Bitcoin network presents an interesting application of CAP principles in a decentralized context. It prioritizes partition tolerance and availability over immediate consistency.
When you make a Bitcoin transaction, it's not immediately 'final'. Instead, it becomes more certain over time as more blocks are added to the blockchain. This eventual consistency model allows the network to continue operating even when parts of it are disconnected or under attack.
The trade-off? You need to wait for several confirmations before considering a large transaction truly complete, which can take up to an hour.
Lessons from the Real World
These examples illustrate several key points:
- Context Matters: The right CAP trade-off depends heavily on the specific needs of your application.
- Hybrid Approaches: Many real-world systems don't strictly adhere to CP or AP but use a mix of strategies.
- Evolving Solutions: As technology advances, we're finding new ways to mitigate CAP theorem limitations.
- User Experience Focus: Ultimately, CAP trade-offs are about providing the best possible user experience within technical constraints.
By examining these real-world applications, we can see how the CAP theorem isnt just a theoretical construct but a practical guide for building resilient, scalable distributed systems. As you design your own systems, these examples can serve as inspiration for creative solutions to the ever-present CAP dilemma.
Strategies for Designing CAP-aware Systems
Designing systems with the CAP theorem in mind is like crafting a finely balanced machine. It requires careful consideration, creative problem-solving, and a deep understanding of your specific needs. Let's explore some strategies that can help you navigate the complex landscape of distributed systems design.
1. Know Your Requirements Inside Out
Before diving into the technical details, take a step back and really understand what your system needs to achieve:
- What's the primary function of your application?
- How critical is data consistency to your users?
- Can your system tolerate brief periods of unavailability?
- What's your expected scale and geographical distribution?
Answering these questions will give you a solid foundation for making informed CAP trade-offs.
2. Embrace Eventual Consistency Where Appropriate
Eventual consistency can be a powerful tool in your CAP-aware design arsenal. It allows you to prioritize availability and partition tolerance while still providing a form of consistency over time.
Consider implementing eventually consistent models for non-critical data. For example, in a social media application, likes and comments could be eventually consistent, allowing for high availability even during network partitions.
3. Implement Multi-Version Concurrency Control (MVCC)
MVCC is like having a time machine for your data. It allows multiple versions of data to coexist, which can be particularly useful in distributed systems.
By implementing MVCC, you can improve availability and concurrency while maintaining a level of consistency. Users can always read a consistent (though potentially slightly outdated) version of the data, while writes can proceed without blocking reads.
4. Use Conflict Resolution Techniques
In distributed systems, conflicts are inevitable. Preparing for them is key to maintaining system integrity.
Implement conflict resolution strategies such as:
- Last-write-wins (LWW)
- Custom merge functions
- Vector clocks to track causality
These techniques can help your system automatically resolve conflicts that arise due to network partitions or concurrent updates.
5. Leverage Caching Strategically
Caching is like having a cheat sheet for your data. It can significantly improve availability and performance, but it needs to be managed carefully to avoid consistency issues.
Consider using:
- Read-through and write-through caching
- Cache invalidation strategies
- Time-to-live (TTL) settings
Remember, caches introduce another layer of complexity in terms of consistency, so use them judiciously.
6. Implement Circuit Breakers
Circuit breakers are like safety valves for your system. They can prevent cascading failures in distributed systems by failing fast and providing fallback mechanisms.
By implementing circuit breakers, you can improve your system's resilience to network partitions and maintain a level of availability even when parts of the system are struggling.
7. Design for Failure
In distributed systems, failure is not just possible – it's inevitable. Design your system with this reality in mind:
- Implement retry mechanisms with exponential backoff
- Use bulkheads to isolate failures
- Design fallback mechanisms for critical operations
By preparing for failure, you can create a system that gracefully handles the challenges posed by the CAP theorem.
8. Consider CRDT (Conflict-Free Replicated Data Types)
CRDTs are like magic building blocks for distributed systems. They are data structures that can be replicated across multiple computers in a network, where the replicas can be updated independently and concurrently without coordination between the replicas, and it is always mathematically possible to resolve inconsistencies that might result.
By using CRDTs, you can achieve strong eventual consistency without sacrificing availability or partition tolerance.
9. Implement Sharding
Sharding is like dividing a big problem into smaller, more manageable pieces. By partitioning your data across multiple nodes, you can improve scalability and reduce the impact of network partitions.
However, be aware that sharding introduces its own complexities, especially when it comes to maintaining consistency across shards.
10. Monitor and Measure Religiously
You can't improve what you don't measure. Implement comprehensive monitoring and alerting for your distributed system:
- Track consistency levels
- Monitor network partitions
- Measure response times and availability
This data will be invaluable in understanding how your CAP trade-offs are playing out in the real world and where improvements can be made.
11. Educate Your Team
Finally, remember that designing CAP-aware systems is a team effort. Ensure that everyone involved in the design, development, and operation of

Limitations and Criticisms of CAP Theorem
While the CAP theorem has been a cornerstone of distributed systems theory for over two decades, it's not without its limitations and critics. As with any widely accepted principle, it's crucial to understand not just its strengths, but also its weaknesses and the ongoing debates surrounding it. Let's peel back the layers and examine some of the key criticisms and limitations of the CAP theorem.
Oversimplification of Complex Systems
One of the primary criticisms of the CAP theorem is that it presents a somewhat binary view of distributed systems, which can oversimplify the nuanced reality of modern architectures.
In practice, consistency and availability aren't all-or-nothing properties. There's a spectrum of consistency models ( strong, eventual, causal, etc.) and various degrees of availability. The CAP theorem doesn't capture these nuances, potentially leading to overly simplistic design decisions.
For instance, a system might provide high availability for reads but lower availability for writes, or it might offer different consistency guarantees for different types of data. These subtleties are not readily apparent in the basic CAP model.
Focus on Extreme Conditions
The CAP theorem primarily addresses behavior during network partitions, which, while important, are relatively rare events in many systems. Critics argue that this focus on extreme conditions may lead designers to make suboptimal choices for the more common, non-partitioned state of the system.
It's a bit like designing a car solely based on how it performs in a crash test, while neglecting its everyday driving characteristics. While crash safety is crucial, it shouldn't be the only consideration in car design.
Neglect of Other Important System Properties
By focusing solely on consistency, availability, and partition tolerance, the CAP theorem might lead designers to overlook other critical system properties. Factors like latency, throughput, and data freshness can be equally important in many scenarios.
For example, a system might be consistent and available, but if it's excruciatingly slow, it might as well be unavailable from a user's perspective. The CAP theorem doesn't address these performance aspects directly.
The "2 out of 3" Misconception
A common misinterpretation of the CAP theorem is the idea that a distributed system must always choose exactly two out of the three properties. In reality, the theorem only states that during a network partition, a system must choose between consistency and availability.
This misconception can lead to flawed system designs where designers believe they must entirely sacrifice one property, when in fact more nuanced trade-offs are possible.
Evolution of Network Technologies
As network technologies have evolved, some argue that the fundamental assumptions of the CAP theorem may need revisiting. Modern networks are often more reliable and have lower latency than when the theorem was first proposed.
While network partitions can still occur, their frequency and impact might be different in today's landscape, potentially altering the calculus of CAP trade-offs.
Lack of Consideration for Time and Scale
The CAP theorem doesn't explicitly account for the role of time in consistency models. In real-world systems, consistency often has a temporal aspect – data might become consistent after a certain period, even if it wasn't immediately consistent.
Similarly, the theorem doesn't directly address how trade-offs might change as a system scales. A small system might easily achieve all three properties, while a global, highly distributed system faces more significant challenges.
Alternative Models and Refinements
In response to these limitations, researchers and practitioners have proposed various refinements and alternative models:
- PACELC theorem: This extends CAP by considering system behavior both during partitions (PA/EL) and in the absence of partitions (PC/EC).
- BASE (Basically Available, Soft state, Eventual consistency): This model provides an alternative to ACID for designing systems that prioritize availability.
- The "CAP Twelve Years Later" paper by Eric Brewer himself, which revisits and clarifies some aspects of the original theorem.
These alternatives and refinements aim to provide a more nuanced understanding of distributed systems trade-offs.
